Cabang Amerika dari Asosiasi Komputasi
Ia memenangkan Penghargaan Makalah Terbaik dalam Jurnal Linguistik. Peneliti Kim adalah LG
Saat bekerja sebagai pekerja magang di Laboratorium Kecerdasan Super Lembaga Penelitian AI, ia bekerja sama dengan Lee Mun-tae, kepala Laboratorium Kecerdasan Super, dan peneliti lain di bidang AI generatif (kecerdasan buatan).
Kami mengembangkan "BIGGEN BenchMARK" untuk mengevaluasi kinerja model. Tim peneliti yang dipimpin Kim termasuk peneliti dari Universitas Yonsei dan Institut Teknologi Massachusetts.
Para peneliti dari sejumlah universitas, termasuk MIT, berpartisipasi dalam penelitian ini. Metode evaluasi yang ada untuk model AI generatif bergantung pada indeks abstrak seperti fleksibilitas dan tidak berbahaya, dan hasilnya mungkin berbeda dari yang diperoleh manusia.
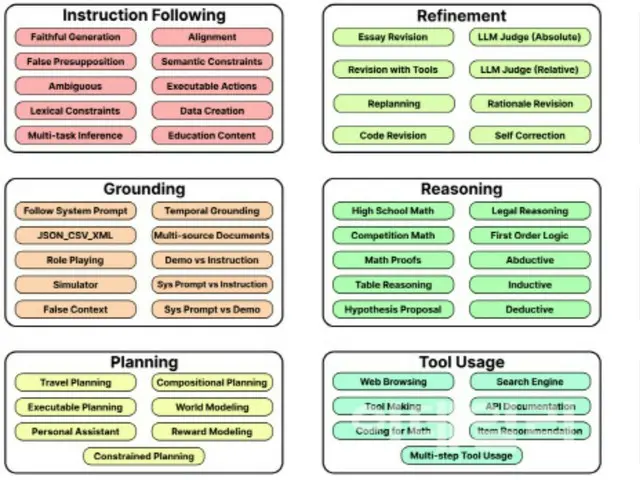
Ada beberapa kasus yang seperti ini. Sementara itu, BigGen BenchMARK mengklasifikasikan kemampuan yang harus dimiliki model AI menjadi sembilan jenis, seperti kemampuan menjalankan instruksi, membuat inferensi logis, dan memahami beragam bahasa dan konteks budaya. 77
Terdiri dari 765 item yang mengevaluasi kinerja keterampilan. LG AI Research Institute menggunakan pembandingan BigGen untuk mengevaluasi 103 model AI generatif dan melakukan validasi silang dengan sekelompok ahli.
Bukti menunjukkan tingkat validitas yang tinggi.
2025/05/02 09:24 KST
Copyrights(C) Edaily wowkorea.jp 101